Tensorflow 기초
★ 공부 출처 : https://www.opentutorials.org/course/4570/28965
오리엔테이션 - 생활코딩
수업소개 딥러닝이라는 이름으로 유명해진 인공신경망과 이를 구현하는 것을 도와주는 도구 텐서플로우 라이브러리를 소개하면서, 텐서플로우 라이브러리부터 전체 AI까이 이어지는 계층구조
www.opentutorials.org
Tensorflow로 해결하려는 것?
--> 지도학습 영역의 회귀, 분류 문제
회귀 : 숫자로 된 결과를 예측하는 것.
분류 : 카테고리(범주) 형태를 예측하는 것.
--> 회귀, 분류 문제를 해결하기 위해 사용하는 것이 머신러닝 알고리즘이다.
ex) Decision Tree, Random Forest, KNN, SVM, Neural Network
Neural Network : 사람의 두뇌가 동작하는 것을 모방해서 학습을 할 수 있도록 고안된 알고리즘
(=인공 신경망 = Deep Learning)
간편하게 사용할 수 있는 Deep Learning 도구들이 많이 생겨났다.
--> 코딩에서는 이를 Library라고 부름. 대표적인 것으로 TensorFlow, PyTorch, Caffee2, theano가 있다.
지도학습을 하기 위해서는? (머신러닝 프로세스)
1. 과거의 데이터를 준비한다.
독립변수(원인) / 종속변수(결과)
2. 모델의 구조를 만든다.
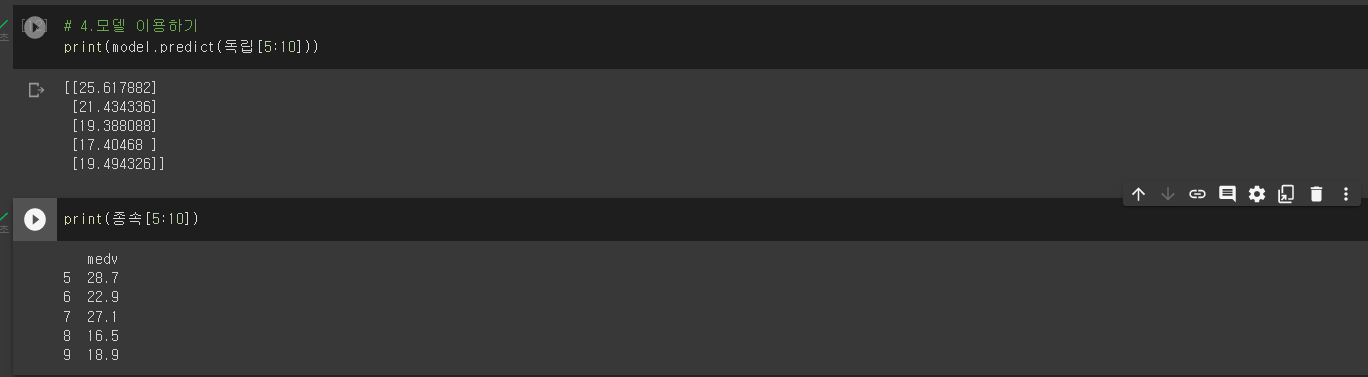
3. 데이터로 모델을 학습(FIT)한다.
4. 모델을 이용한다.
Pandas 사용 실습
- 파일 읽어오기 : pd.read_csv('/경로/파일명.csv')
- 모양 확인하기 : print(데이터.shape)
- 칼럼 선택하기 : 데이터[['칼럼명1', '칼럼명2', '칼럼명3']]
- 칼럼 이름 출력하기 : print(데이터.columns)
- 맨 위 5개 관측치 출력하기 : 데이터.head()
csv : ,을 사용해서 항목을 구분하여 저장한 데이터




epochs --> 학습할 횟수
손실 (loss)
학습이 얼마나 정확히 진행되었는지 평가하는 지표이다.

LOSS가 0이 될수록 학습이 잘 된 모델이다.
레모네이드 실습


--> 많은 횟수를 학습시킬 때 출력되는 것을 막기 위해서는 epochs 옆에 verbose = 0을 해준다.

이상치
정상 범주에서 크게 벗어난 값을 의미한다.
이상치로 인해 평균이 대표성을 갖지 못할 경우 대안으로 사용하는 것이 중앙값이다.


보스턴 실습




집값 = -0.09414777 * x1 + 0.04797078 * x2 + -0.02008947 * x3 + 2.654368 * x4 + -2.8365178 * x5 + 5.249078 * x6 + -0.01055513 * x7 + -1.0753189 * x8 + 0.20022132 * x9 + -0.01139516 * x10 + -0.5280915 * x11 + 0.01196622 * x12 + -0.4605365 * x13 + 9.022964
딥러닝 워크북


종속변수에 따라 양적, 범주형으로 달라진다.
양적의 경우 회귀 문제이고, 범주형의 경우 분류 문제이다.

원핫인코딩
범주형의 데이터를 1과 0의 데이터로 바꾸어주는 것을 말한다.



수식이 3가지인 이유
--> setosa, virginica, versicolor 중 어떤 것인지 구별해야 하기 때문이다.
소프트맥스
입력받은 값을 출력으로 0~1사이의 값으로 모두 정규화하며 출력 값들의 총합은 항상 1이 되는 특성을 가진 함수이다.
+ 시그모이드
퍼셉트론을 좀 더 구체적으로 보면 다음과 같다.

분류에 사용하는 loss는 crossentropy이고, 회귀에 사용하는 loss는 mse이다.
분류 문제에서는 loss보다 accuracy가 더 좋은 평가 지표가 된다.

아이리스 실습




y1 = 1.4496394 * x1 + 2.4152737 * x2 + -3.9665186 * x3 + -4.825588 * x4 + 2.0981247
y2 = 0.76702505* x1 + 0.5128809 * x2 + -1.1200129 * x3 + -0.78761667 * x4 + 0.76537913
y3 = -0.65899414 * x1 + -0.33183038 * x2 + 0.8179453 * x3 + 1.7112354 * x4 + -1.4670593
히든레이어


히든레이어 실습
<보스턴>



데이터 타입의 문제 & NA값의 문제를 해결하는 데이터 전처리 방법
데이터 타입을 알기 위해서는 .dtypes 하면 된다.
원핫인코딩을 하기 위해서는 데이터 타입이 카테고리 혹은 오브젝트 타입이어야 한다.
*NA란?
Not Available의 약자로, 결측치를 뜻한다.
이를 해결하기 위해 NA값에 평균값을 넣어주는데, 평균값을 계산하기 위해서는 .mean()을 해주면 된다.
그 후, mean값을 NA에 넣어주기 위해서는 .fillna(mean) 해주면 된다.
실습

품종이 저런 식으로 되어 있는 것을 알 수 있다.
이를 해결하기 위해 데이터 타입을 체크하고, 변경해준다.

그 후, 원핫인코딩을 하고 NA값을 확인한다.


BatchNormalization
BatchNormalization은 Dense와 Activation 사이에 적어주는 것이 좋기 때문에 Dense와 Activation을 따로 분리하는 것이 좋다.
실습